Analyze Results
We summarize key findings on AppForge-Bench with figures and tables from the paper. Overall, even frontier LLMs achieve modest success on full Android app development, while compilation feedback improves compile rates but not functional correctness proportionally.
Key Findings
- End-to-end development is hard: the best-performing model reaches sub-20% functional success; many generated apps still crash at runtime even after passing tests.
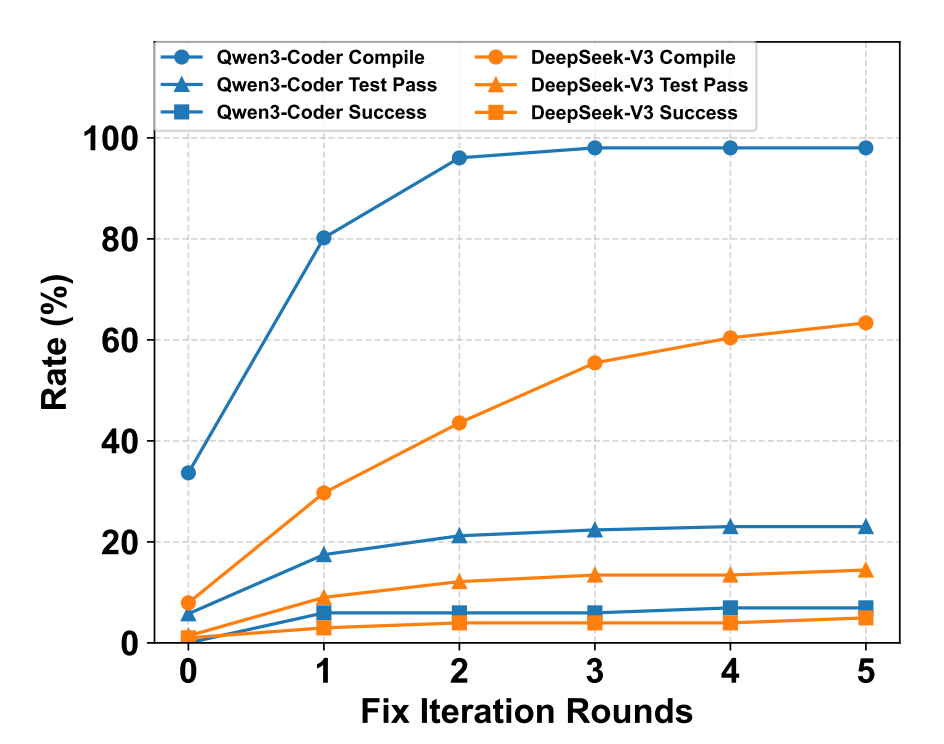
- Compilation feedback helps compile rate (large jumps for some models), yet Test Pass and Success saturate after a few rounds.
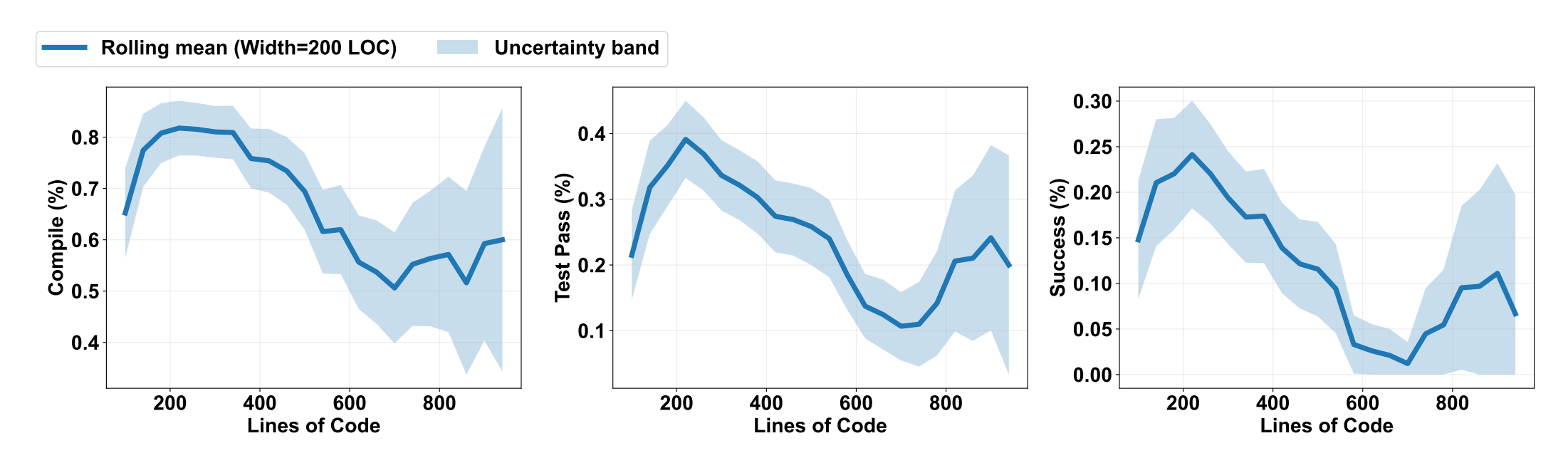
- Task complexity matters: success decreases as LOC grows; simple apps can be robust with proactive exception handling.
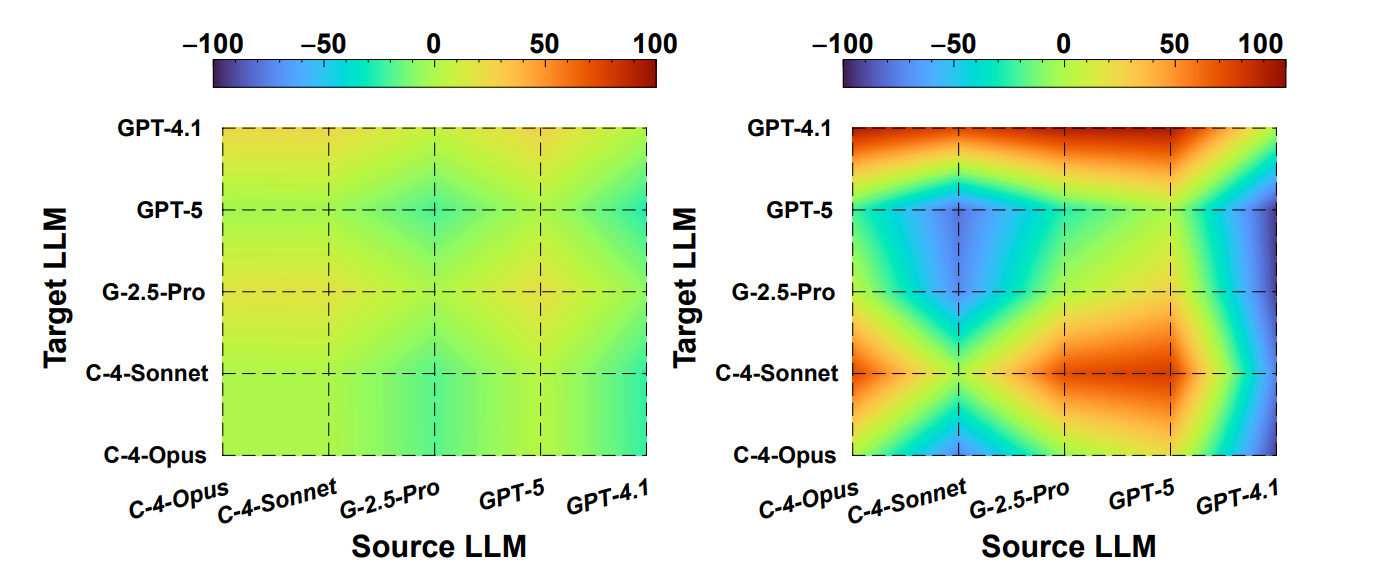
- Evasion behaviors: some models delete faulty logic merely to pass compilation, harming functionality and increasing fail-to-start cases.
Figures
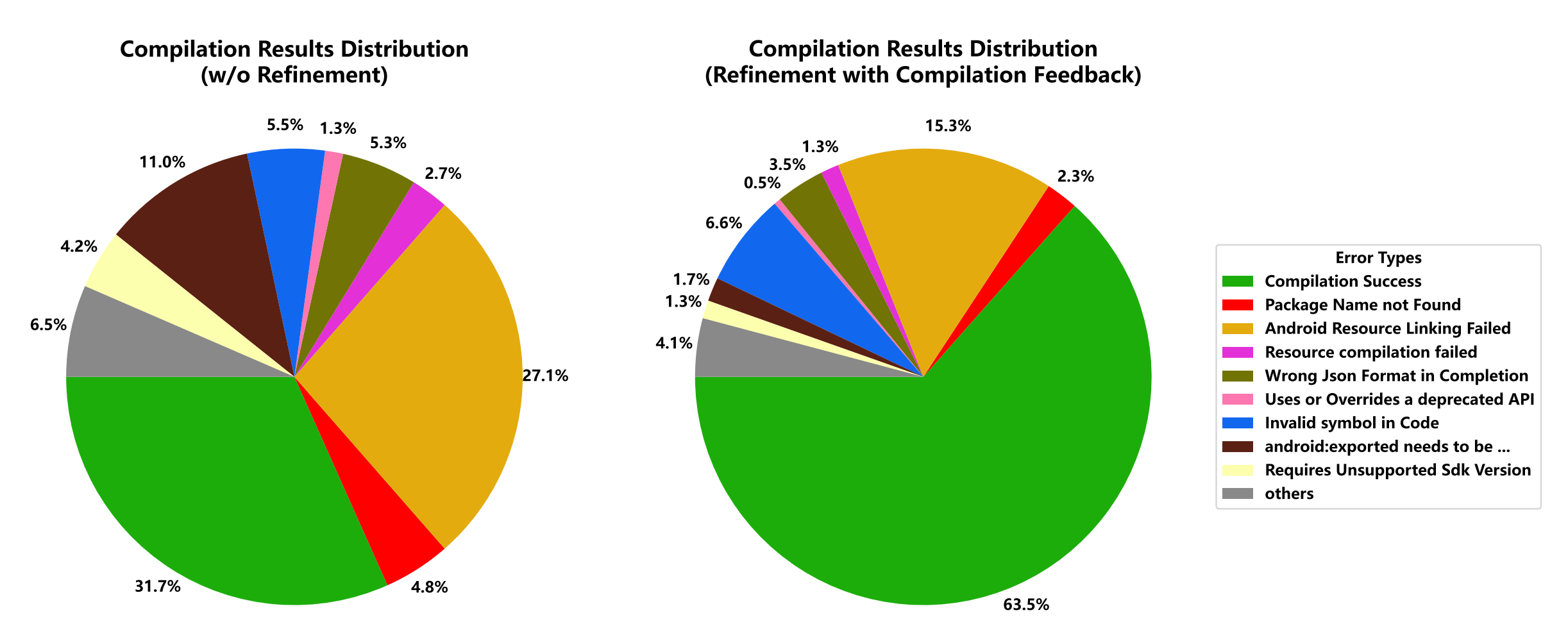
Tables
Table 2 · Performance of Coding Agents on AppForge
SWE = mini-SWE-agent; CC = Claude Code.
| Agent | LLM | #File | #LOC | Compile | Test Pass | Success |
|---|---|---|---|---|---|---|
| SWE | Claude-4-Opus | 10.76 | 558.40 | 71.29% | 24.61% | 11.88% |
| SWE | Qwen3-Coder | 8.42 | 430.94 | 88.12% | 22.21% | 6.93% |
| CC | Qwen3-Coder | 5.34 | 280.66 | 76.24% | 14.64% | 6.93% |
Agent frameworks provide modest gains; absolute success remains low.
Table 3 · GPT-5 Reasoning Levels on AppForge
| Level | #File | #LOC | Compile | Test Pass | Success |
|---|---|---|---|---|---|
| Low | 5.91 | 280.91 | 22.77% | 8.41% | 2.97% |
| Medium | 7.61 | 321.96 | 27.72% | 11.11% | 3.96% |
| High | 7.76 | 354.59 | 45.54% | 21.90% | 14.85% |
More reasoning helps across metrics but still far from practical Android development.
Table 4 · Runtime Crash Analysis across LLMs
| Model | Native Crash (w/o Fix) | Native Crash (w/ Fix) | Failed to Start (w/o Fix) | Failed to Start (w/ Fix) |
|---|---|---|---|---|
| GPT-4.1 | 0.0 | 11.0 | 2.0 | 66.0 |
| Claude-Opus | 48.0 | 48.0 | 9.0 | 11.0 |
| Gemini-Pro | 25.0 | 37.0 | 14.0 | 21.0 |
| GPT-5-High | 21.0 | 0.0 | 5.0 | 25.0 |
Evasive “compile-only” fixes often backfire at runtime; many crashes are native.
* Percentages shown as %; web tables are simplified for readability. See Docs for the full paper.